Overview
We evaluated leading open-source deepfake detectors the way a buyer should: on attacks held out of training, under the conditions production imposes, and stratified so no group hides behind a strong average. The two detectors that scored a perfect clean number fell the furthest; six others lost less ground but still slipped. The pattern is the same across the field: clean-benchmark accuracy does not survive the test getting harder.
Detectors that score near-perfect on clean benchmarks fall to near-random once attacks are unseen and media is reprocessed the way platforms reprocess it.
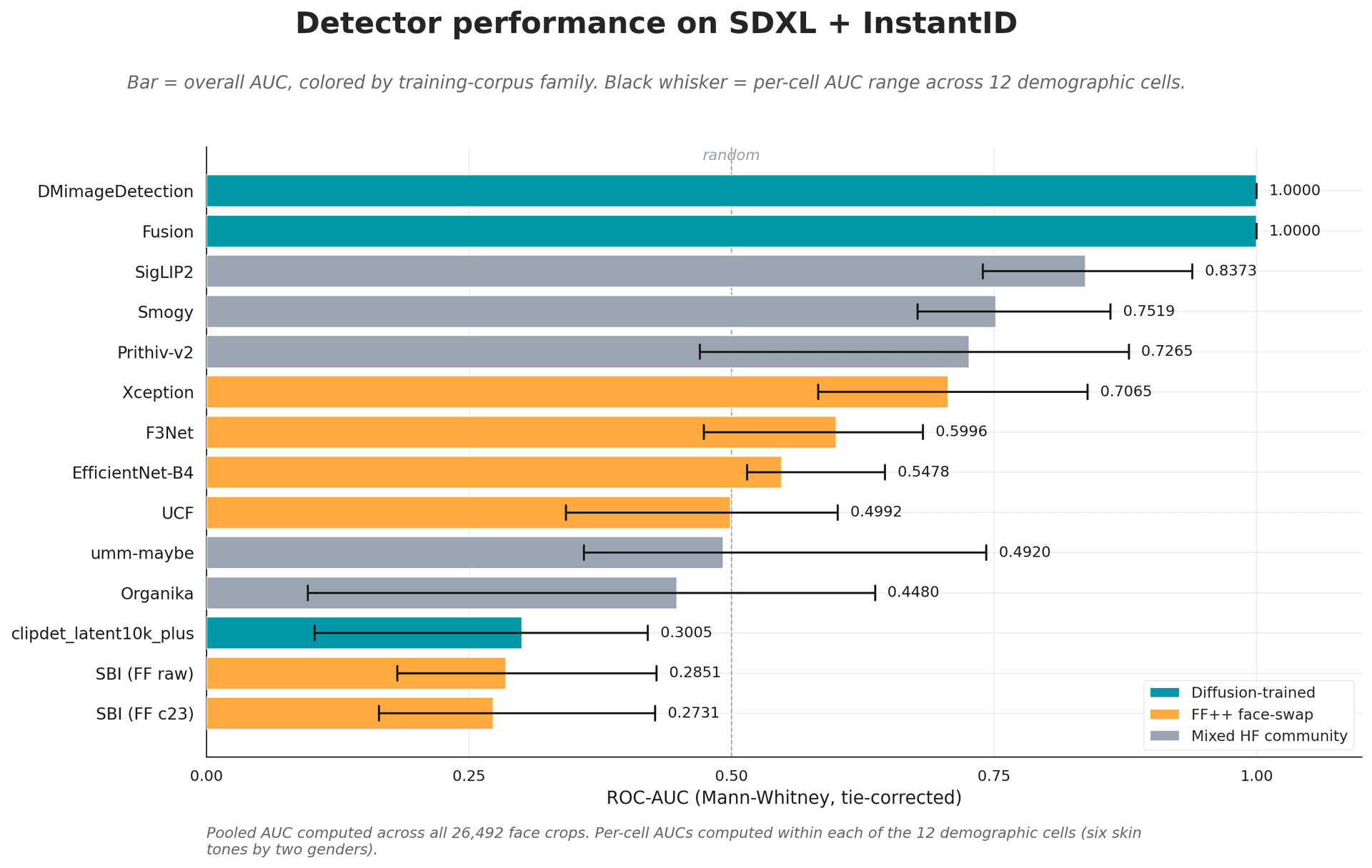
Source: Margen open-source detector benchmark · 14 detectors.
The clean leaderboard
On a clean benchmark, the field looks healthy. A handful of detectors post near-perfect scores and a tidy ranking emerges. This is the table a buyer usually sees, and the number a vendor usually quotes.
| Detector | Training family | Clean AUC | Clean-board tier |
|---|---|---|---|
| DMimageDetection | Diffusion-trained | 1.0000 | Top of clean board |
| Fusion | Diffusion-trained | 1.0000 | Top of clean board |
| SigLIP2 | Mixed community | 0.8373 | Mid clean board |
| Smogy | Mixed community | 0.7519 | Mid clean board |
| Xception | Face-swap | 0.7065 | Mid clean board |
| F3Net | Face-swap | 0.5996 | Near random |
| UCF | Face-swap | 0.4992 | Near random |
| clipdet_latent10k | Diffusion-trained | 0.3005 | Near random |
| SBI (FF c23) | Face-swap | 0.2731 | Near random |
Clean-benchmark ROC-AUC on leading open-source detectors. The rest of this piece is about what happens to these numbers once the test stops being clean.
The format confound
A large share of reported detector skill comes from reading compression signature, not synthesis artifacts. When real and fake media are forced through one encoding pipeline so the two share a format, the apparent accuracy collapses.
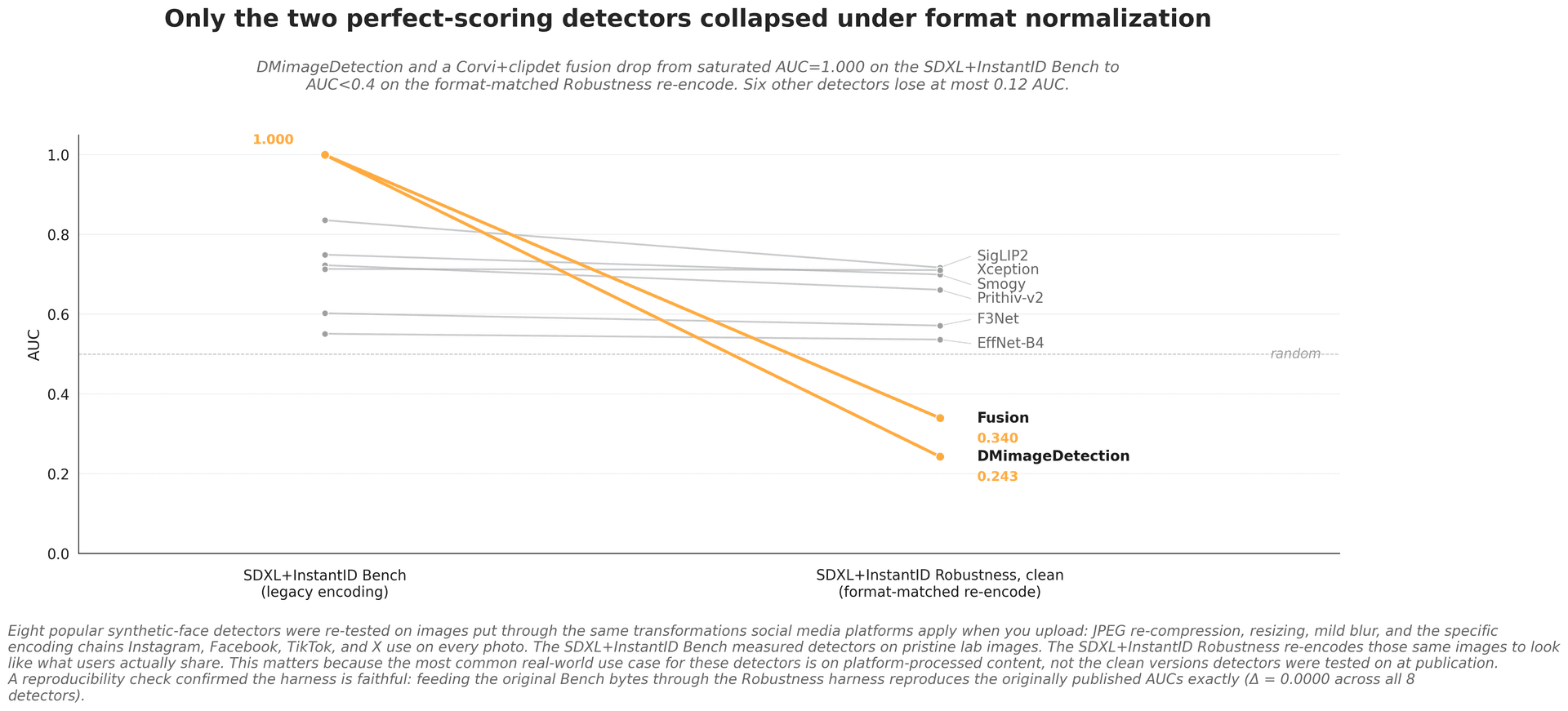
The control is a few lines. Score the detector as-is, then re-encode both classes through one pipeline and score again. The gap is the share of accuracy that was reading format rather than synthesis.
1from sklearn.metrics import roc_auc_score2# Score without parity: real and fake arrive in different formats4auc_raw = roc_auc_score(y_true, detector.score(images))5# Re-encode every image through ONE pipeline, then score again7parity = [reencode(img, codec="h264", quality=70) for img in images]8auc_parity = roc_auc_score(y_true, detector.score(parity))9# The gap is the "skill" that was reading format, not artifacts11print(round(auc_raw - auc_parity, 3))
Per-group failure
Pooled accuracy hides subgroup failure. We break every result out across skin-tone and gender groups and report the maximum disparity, not the average, so a failing group cannot be averaged away.
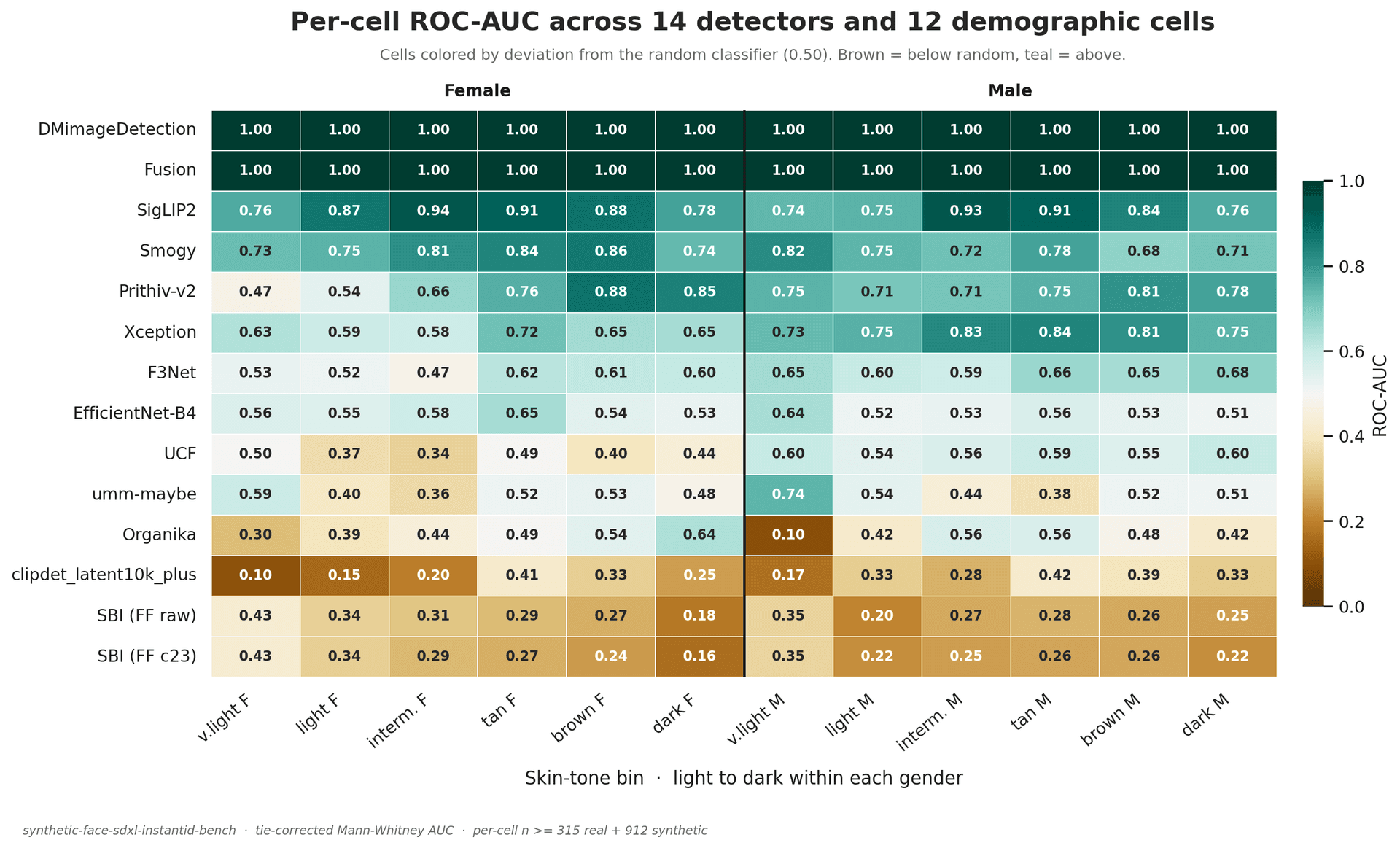
Source: Margen open-source detector benchmark · 14 detectors. Skin-tone labels are imperfect; read per-group results as directional, not precise.
Platform degradation
Real-world re-encoding, resizing, and recompression move numbers that clean-lab benchmarks never test. A detector validated only on pristine images is not validated for production.
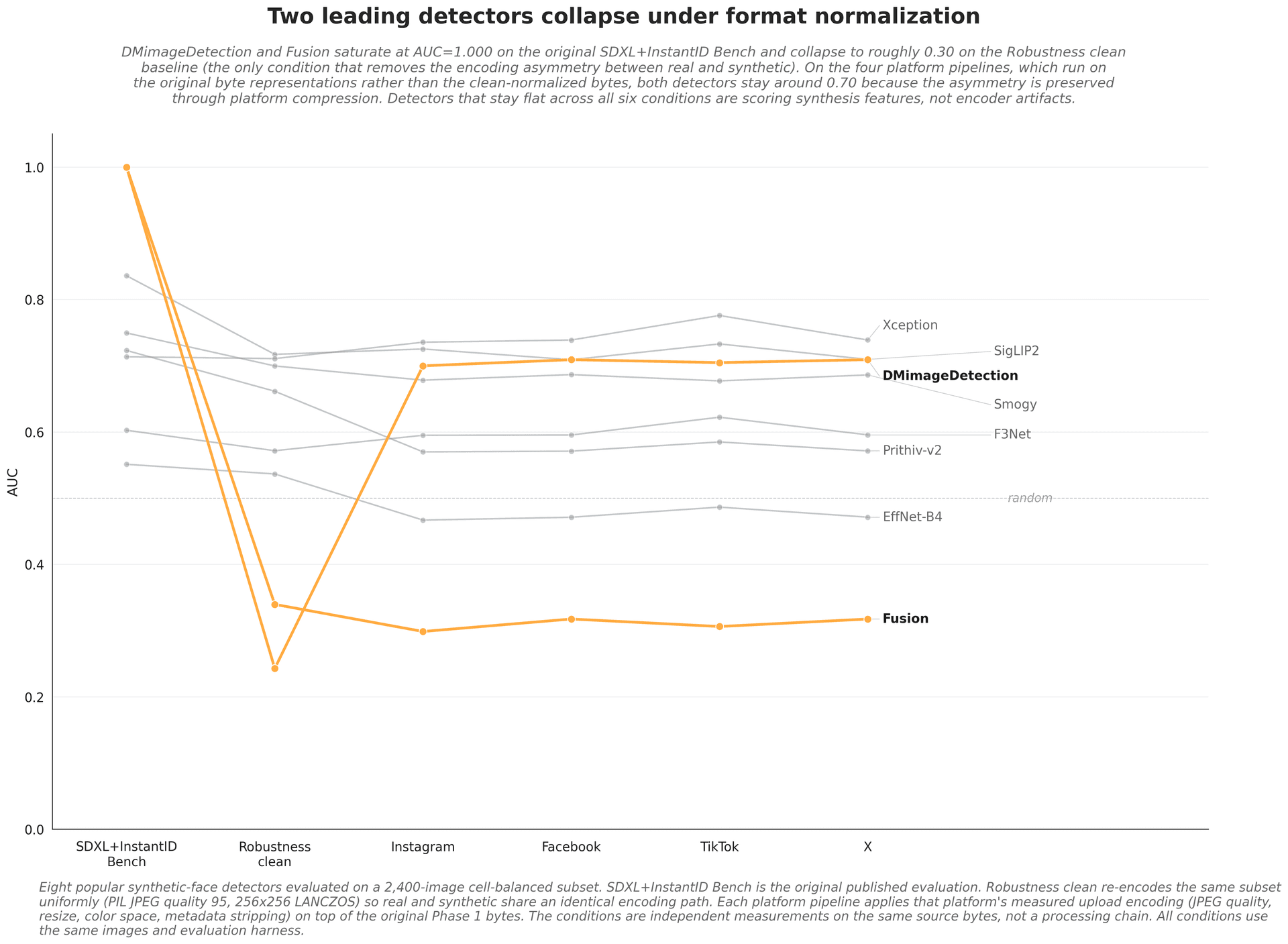
What this means for buyers
A published accuracy near 1.0 is not evidence a detector will hold against fraud. Before you rely on one, it should be tested on unseen generators, under platform-realistic conditions, and broken out by group. That is what a Margen evaluation produces.
Cite this paper
This benchmark is published openly with a permanent DOI. Cite the immutable record, not this page.
Cite this paper
Pick a format. Copy the string.
Babalola, D.. (2026). Deepfake Detector Robustness Under Social-Media Re-encoding. Zenodo. https://doi.org/10.5281/zenodo.20781389